
Table of Contents
Did you know that the market for invoice factoring, with a valuation of USD 2.32 billion in 2023, is anticipated to grow to USD 4.55 billion by the year 2030? This growth trajectory represents a CAGR of 10.11% throughout the forecast period running from 2024 to 2030.
Scarlet is an automated document processing system, developed by High Peak Software. It is powered by intelligent machine-learning algorithms.
It carries out a geometrical analysis of a document and accurately extracts relevant data.
Scarlet is a customizable solution capable of processing any kind of document, including images and non-searchable PDF files, specifically tailored for your business requirements.
Client overview
Our client is a provider of payment processing and information management services in the United States commercial and government vehicle fleet industry, Canada, South America, Europe, Asia, and Australia.
They simplify the complexities of payment systems across continents and industries, including fleet, corporate payments, and health.

Problems

Our client has thousands of existing customers. They processed over 8000 invoices on a daily basis.
Creditors and debtors send payment information over emails via different avenues, including invoices, bank checks, drafts, etc. This information is either included in the body of the email or as an email attachment.
Because these invoices came from disparate sources, they were in various formats and did not have a standardized template. This made it even more difficult to identify.
The client employed a large manual workforce to process these invoices and identify their source and format. This entire process required a substantial amount of time, effort, and resource overheads.
For instance, processing 8000 invoices took more than 8 hours and at least 5–8 employees on a given business day.
In addition, our client was facing other problems, including:
- Compromised productivity: Manual classification of documents received in different formats from different sources was time-consuming and counter-productive.
- Highly error-prone processes: Because the email attachments contained sensitive payment-related data, even the smallest error could prove to be catastrophic to business. Further, the manual processing of these emails was a highly error-prone process.
- Overhead costs: Manually processing such large volumes of payment-related information required a significant amount of resources and was an expensive affair.
The client wanted to automate these manual processes and approached High Peak to facilitate business process automation. To achieve this, we introduced our product Scarlet for automating invoice factoring.
Challenges

Automation of document classification
The client workforce had to manually read thousands of emails per day, check for attachments, and classify documents accordingly. Automating this operation to improve the processing speed of emails and efficiency of the overall process was a challenge.
Data centralization
Unifying disparate sources to include multiple formats and templates especially when there is no definite standardization, posed a major challenge for the team.
Data extraction
Scarlet carries out data extraction for two kinds of data: structured and unstructured. These would include free text and tables present in the email body and digital attachments. Further, the digital attachments are of various types, including CSV files, non-readable PDFs, TIFF, PNG, etc. Extracting data from a plethora of scanned and image file formats accurately posed a great challenge.
Data accuracy
Because the financial information is extremely sensitive, the High Peak team had to ensure that the system is capable of extracting data with the highest levels of accuracy.
Data security
As mentioned above, our client was dealing with banking and financial data, which is extremely sensitive. The High Peak team had to ensure that extraction of data from different sources was performed in such a way that such sensitive data was secure and tamper-proof.
Scarlet Automates Invoice Factoring

The automation of invoice factoring is two-fold. One is on the creditor’s side and, the other, on the debtor’s side.
The invoice factoring automation process carried out by Scarlet for both vendors and debtors is discussed in detail below:
Automated document processing: structured and unstructured data
Creditors and debtors send payment information via different avenues, including invoices, bank checks, drafts, etc. This information is either included in the body of the email or as an email attachment. Further, the email attachments are of various types, including CSV files, non-readable PDFs, TIFF, PNG, etc.
Scarlet first carries out a geometrical analysis of the document. This process analyzes the document and draws out the shape of the content in the document.
For example, if the document contains a table, it would be identified as such by its even spacing, rows and columns, etc., whereas unstructured data would be identified by its free flow of text.
Each content or data in the document is associated with attributes such as font size, etc. Scarlet analyzes whether the text is bold, italicized, or indented, and performs a hierarchical mapping of all contents in the document, mapping parent data with child data, and so on, in the form of a tree.
This way, even unstructured data is given a specific structure and is made configurable. The required output can be customized by setting certain rules for the data to be extracted.
For example, if the user requires only the invoice number and the bill amount from an invoice document, the system extracts only those, leaving out other trivial data, and presents them as the final, structured output.
Scarlet achieves this by employing a complex combination of convolutional neural networks, recurrent neural networks, and segmentation, to analyze and extract required data.
Accurate data extraction: improved OCR pipeline
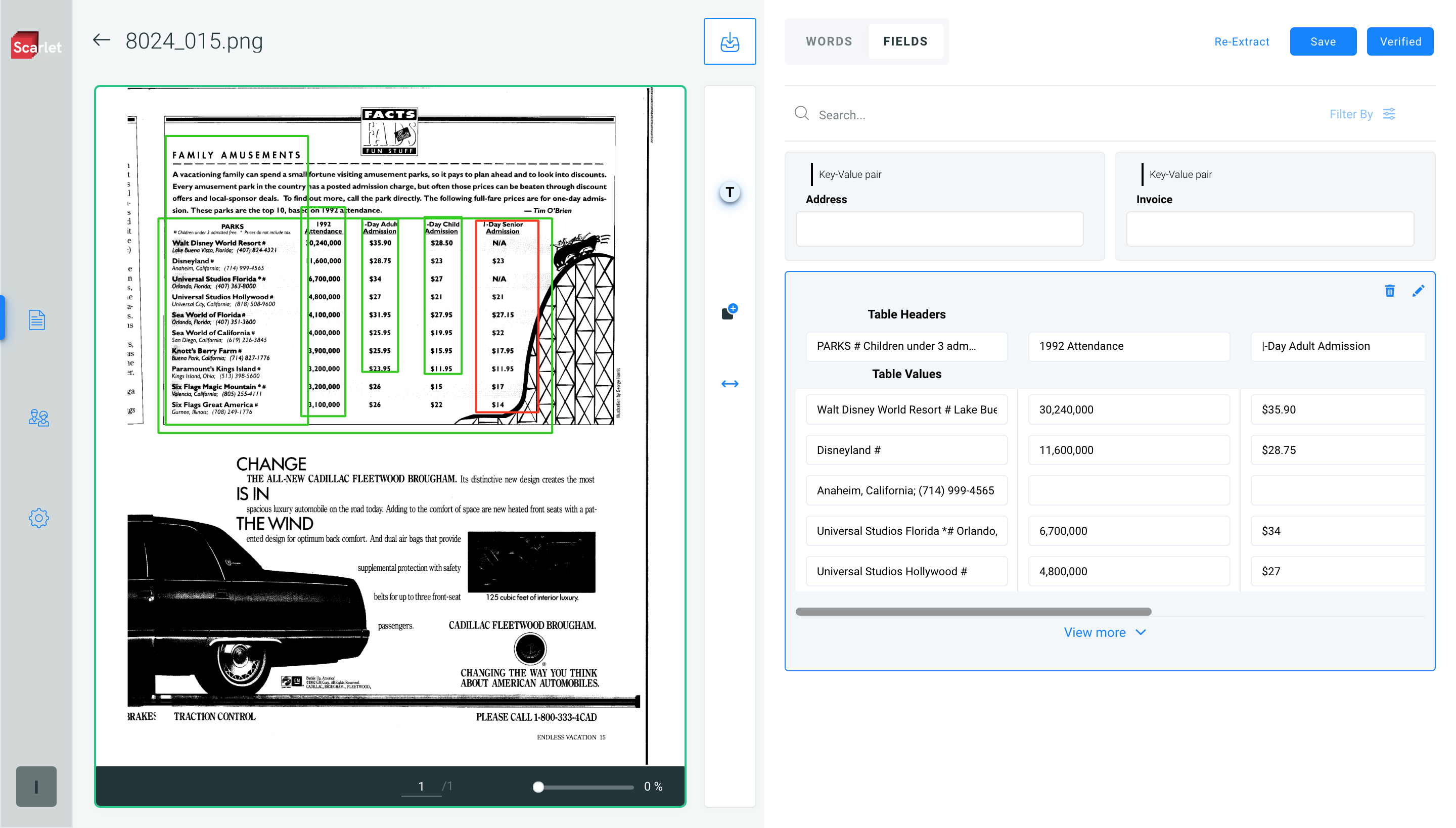
Scarlet can extract data from a document in three formats–tables, sections, and key-value pairs.
A key — value pair is a set of data items that are directly linked to one another.
For example, in an invoice document, the term “Invoice Number” could be a key, and the actual invoice number this term refers to, say, “G1234TY509” could be its value.
Because every document has a different structure, the extraction of data depends on the type of document being processed.
For instance, accounting and billing documents contain row and column values such as serial number, item of purchase, quantity, bill amount, and so on. The extraction of data from such a document will be in the table format.
For structured data, the extraction is simple. However, analyzing unstructured, free-form data is a slightly complex process.
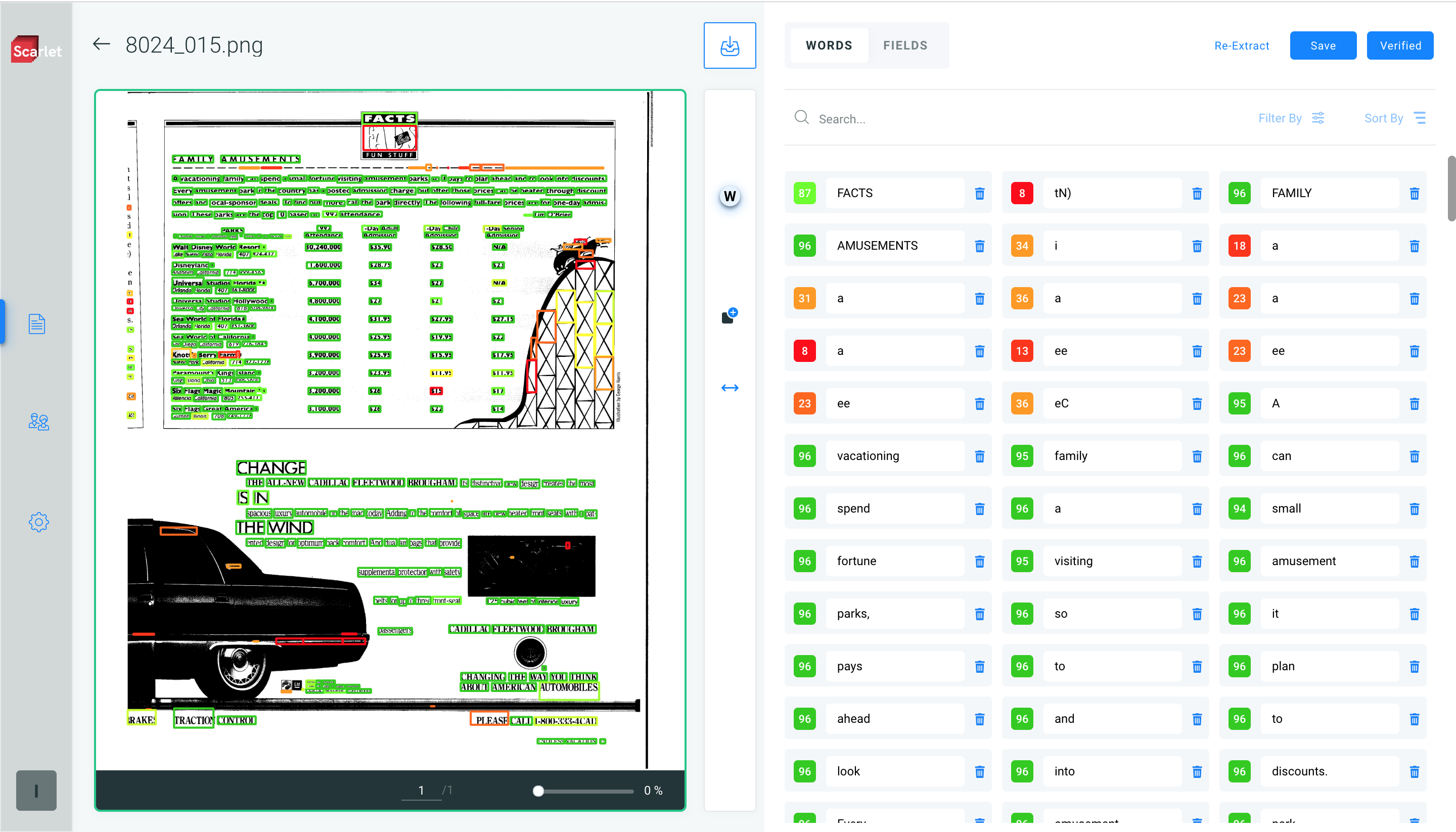
For image files, Tesseract and Google Vision are then employed for performing Optical Character Recognition (OCR) for data extraction. With the help of OCR, Scarlet can scan a large number of documents, thereby improving the processing speed and data extraction time.
Improved data validation
Validation of payment information between the vendor and debtor was being carried out manually. The client workforce had to identify partially extracted information from low-quality images and fill in the data manually. This process was time-consuming and highly error-prone.
With the help of Scarlet, the entire process was automated and is now carried out without any manual intervention, thereby securing confidential data and preventing potential data leaks.
90% data accuracy
Data accuracy is of absolute significance because the client dealt with highly sensitive data that, if compromised or misrepresented, would result in heavy losses.
On average, Scarlet is able to extract data from email attachments with a 90% accuracy.
In addition, the initial development was carried out on test data to monitor and improve Scarlet’s accuracy. Once the High Peak team was able to improve the accuracy, Scarlet began processing actual data.
The accuracy of the extracted data, however, is dependent on the source. For example, if the image file is quite blurred, it is possible to only partially extract data.
Enhanced data security
To enable data security, High Peak employed privileged access inclient data and servers. Access to critical data on the server was limited only to a few select members of the team.
For instance, the High Peak team had access to only one email account for parsing and extracting data for automating inbound payment operations.
The team’s access to the client server was restricted by whitelisted IPs to the client’s VPN.
If you would like to leverage how Scarlet can enable your business to mitigate overhead costs, please contact us now!